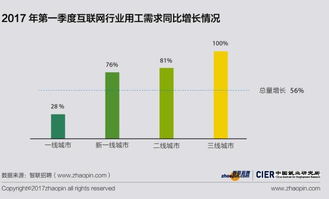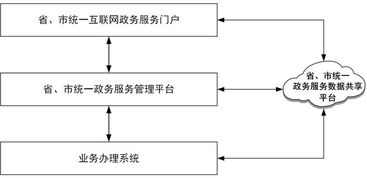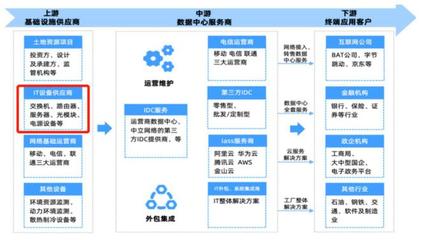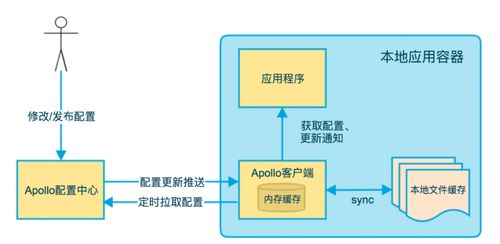
隨著互聯網技術的飛速發展,數據已成為企業的核心資產。為了應對海量、多源、動態的互聯網數據維護需求,傳統的單體應用架構在擴展性、靈活性和維護性方面面臨巨大挑戰。微服務架構憑借其松耦合、獨立部署、技術棧靈活等特點,成為構建高可用、高可擴展互聯網數據維護服務的理想選擇。
一、核心架構概覽
互聯網數據維護服務的微服務架構通常采用分層設計,整體可分為接入層、業務服務層、數據層和基礎設施層。
1. 接入層 (API Gateway)
作為統一入口,負責請求路由、負載均衡、認證鑒權、限流熔斷等。它將外部請求分發至相應的微服務,并聚合返回結果。
2. 業務服務層 (微服務集群)
這是架構的核心,由多個職責單一、獨立自治的微服務構成。典型的服務包括:
- 數據采集服務:負責從互聯網各類公開源(網站、API、RSS等)進行定時或實時數據抓取與解析。
- 數據清洗與標準化服務:對采集到的原始數據進行去重、糾錯、格式轉換、標簽化等處理,形成標準數據格式。
- 數據存儲與索引服務:將處理后的數據持久化到合適的存儲介質(如關系型數據庫、NoSQL數據庫、搜索引擎等),并建立高效索引。
- 數據質量監控服務:實時監控數據完整性、準確性、時效性,觸發告警或自動修復流程。
- 數據更新與同步服務:管理數據的版本、增量更新,并確保跨服務或跨數據中心的數據一致性。
- 元數據管理服務:管理數據目錄、血緣關系、數據字典等,提供數據發現和理解能力。
- 任務調度與編排服務:協調各微服務間的復雜工作流,例如一個完整的數據ETL(抽取、轉換、加載)流程。
3. 數據層
采用多模數據存儲策略,根據數據特性和訪問模式選擇合適的存儲技術:
- 關系型數據庫 (如MySQL, PostgreSQL):存儲高度結構化、事務性強的核心元數據和配置信息。
- NoSQL數據庫 (如MongoDB, Cassandra):存儲半結構化或非結構化的文檔、寬表數據,滿足高吞吐和靈活 schema 需求。
- 搜索引擎 (如Elasticsearch):提供復雜條件查詢和全文檢索能力,用于快速數據檢索。
- 對象存儲 (如S3, OSS):存儲原始網頁快照、圖片、音視頻等大規模非結構化數據。
- 消息隊列 (如Kafka, RabbitMQ):作為服務間異步通信的橋梁,實現解耦和流量削峰,是數據管道的重要組成部分。
4. 基礎設施層
提供底層支撐能力:
- 服務注冊與發現 (如Nacos, Consul):管理微服務的實例注冊與動態尋址。
- 配置中心:統一管理所有微服務的配置,實現動態更新。
- 分布式追蹤與監控 (如SkyWalking, Prometheus+Grafana):監控服務健康、性能指標,追蹤請求鏈路,快速定位問題。
- 容器化與編排 (Docker + Kubernetes):實現微服務的自動化部署、擴縮容和生命周期管理。
二、關鍵交互流程
以一個“數據更新任務”為例,展示微服務間的協作:
- 用戶通過API Gateway提交一個數據更新請求。
- API Gateway將請求轉發至任務調度服務。
- 任務調度服務解析任務,通過服務發現調用數據采集服務,指定目標數據源。
- 數據采集服務執行抓取,將原始數據發布到消息隊列。
- 數據清洗服務從消息隊列消費原始數據,進行清洗處理,并將結果發布到另一消息主題。
- 數據存儲服務消費清洗后的數據,更新主數據庫,并同步更新搜索引擎中的索引。
- 在整個過程中,數據質量監控服務持續從各環節采樣,驗證數據質量。
- 所有服務的日志、指標上報至監控中心,調用鏈路由分布式追蹤系統記錄。
三、架構優勢與挑戰
優勢:
高可擴展性:每個服務可獨立橫向擴展,精準應對不同數據處理環節的壓力。
技術異構性:不同服務可選擇最適合其任務的技術棧(如用Go編寫高并發采集服務,用Python編寫數據清洗腳本)。
容錯與隔離:單個服務故障不易波及其他服務,提高了系統整體韌性。
持續交付:服務獨立部署,加速迭代和上線速度。
挑戰與應對:
復雜性:分布式系統固有的網絡、事務、測試、部署復雜度劇增。需通過完善的 DevOps 工具鏈和清晰的治理規范應對。
數據一致性:跨服務的數據最終一致性需通過 Saga 模式、事件驅動架構等方案保證。
運維監控:必須建立強大的集中式日志、指標監控和鏈路追蹤體系。
服務治理:需妥善處理服務間版本兼容、API契約管理、熔斷降級等問題。
###
設計一個面向互聯網數據維護的微服務架構,核心在于根據數據生命周期(采集、處理、存儲、消費、監控)合理拆分服務邊界,并構建可靠的基礎設施平臺來支撐服務間的通信、協調與可觀測性。成功的架構不僅能高效、穩定地管理海量互聯網數據,更能為上層的數據分析、智能應用提供堅實、靈活的數據底座,驅動業務價值持續增長。